"A contemporary and playful slide designed like a vibrant bulletin board, displaying textual content pinned on colorful sticky notes arranged casually yet clearly across a textured corkboard background. At the top-left corner, the bold, handwritten-style heading "Healthy Eating Made Simple" stands out clearly, accompanied by a short note: "Small habits make big differencespractice daily for lasting wellbeing". Nearby toward the upper center area, a bright yellow note reads "Mindful Portions", with smaller explanatory text: "Listen to your body's signals, eat slowly and stop before overly full". Just below and to the right, a pastel-green note labeled "Include Vegetables" explains succinctly: "Aim to fill half your plate with colorful veggies each day". Moving leftward toward the lower section, a soft-blue sticky note titled "Stay Hydrated" contains the brief sentence: "Drink sufficient water regularly to maintain energy and focus". Decorative elements on the corkboard, such as small doodled fruits, vegetables, and paper clips scattered around the borders, enhance visual warmth and highlight the approachable nature of the presented messages."
TextCrafter:

Investigating Text Insulation and Attention Mechanisms for Complex Visual Text Generation
A project page for complex visual text generation with multi-text insulation, Text-oriented Attention, and the CVTG-2K benchmark.
Ying Tai1†, Nikai Du1†, Rui Xie1*, Zhennan Chen1*, Qian Wang2, Zhengkai Jiang3, Kai Zhang1, Jian Yang1
School of Intelligence Science and Technology, Nanjing University · Jiutian Research · The Hong Kong University of Science and Technology
*Corresponding author(s): Rui Xie, Zhennan Chen.
†These authors contributed equally to this work.




Demo Video
What is TextCrafter?
TextCrafter is a Complex Visual Text Generation (CVTG) framework inspired by selective visual attention in cognitive science, introducing multi-text insulation and text-oriented attention to improve generation quality in complex multi-text scenes.

Datasets for TextCrafter
Explore the dedicated datasets introduced for TextCrafter to evaluate complex visual text generation under more realistic, multi-text, and attribute-aware settings.
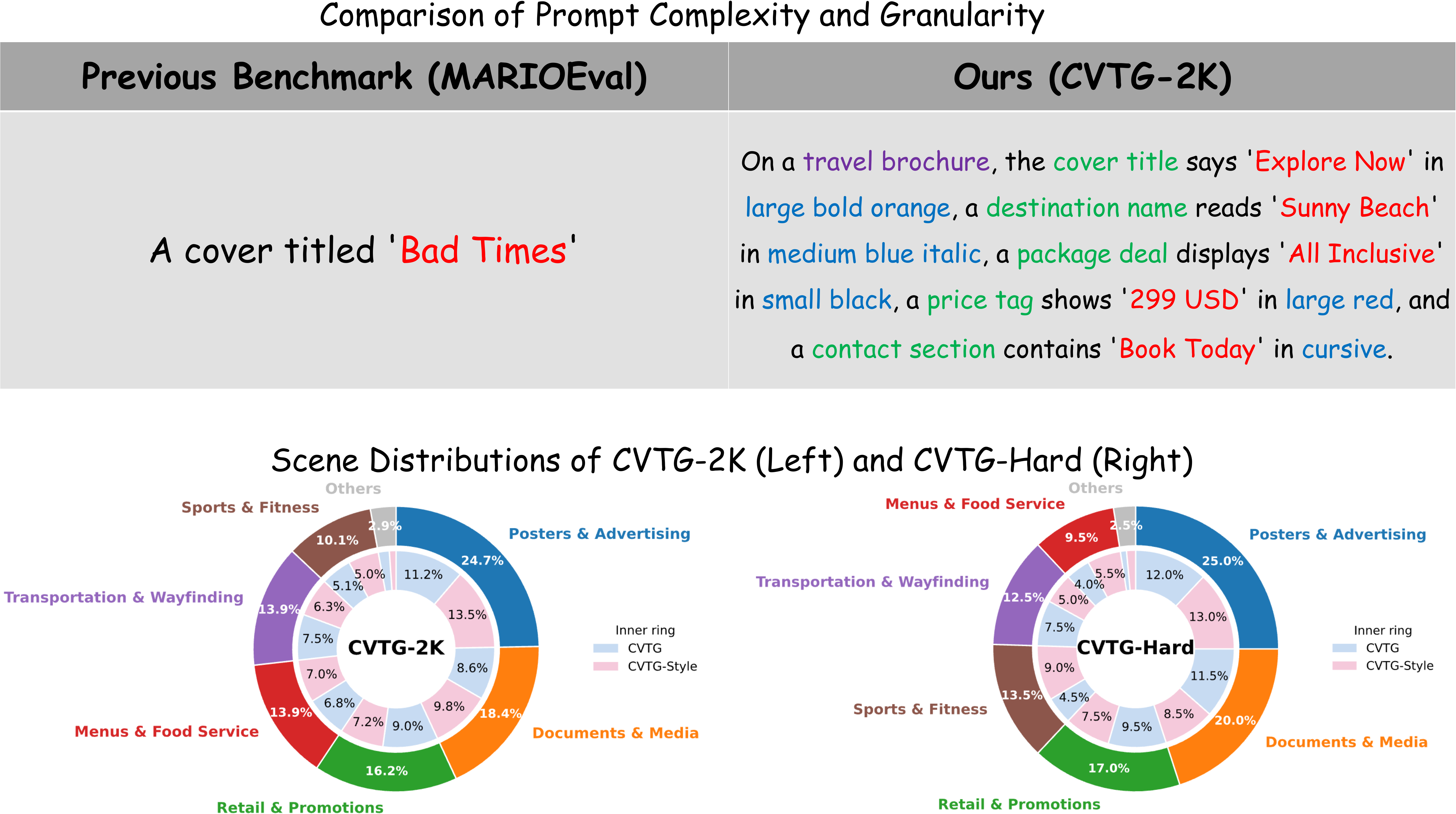
CVTG-2K
CVTG-2K is a dedicated benchmark tailored to the CVTG task. It comprises 2,000 high-quality prompts with diverse region quantities ranging from 2 to 5 and rich visual attributes such as color, font, and size. Unlike previous datasets that predominantly focus on single-region or fixed-template scenarios, CVTG-2K combines global context, multiple text contents, explicit position requirements, and fine-grained visual attributes into a more challenging and realistic evaluation setting.
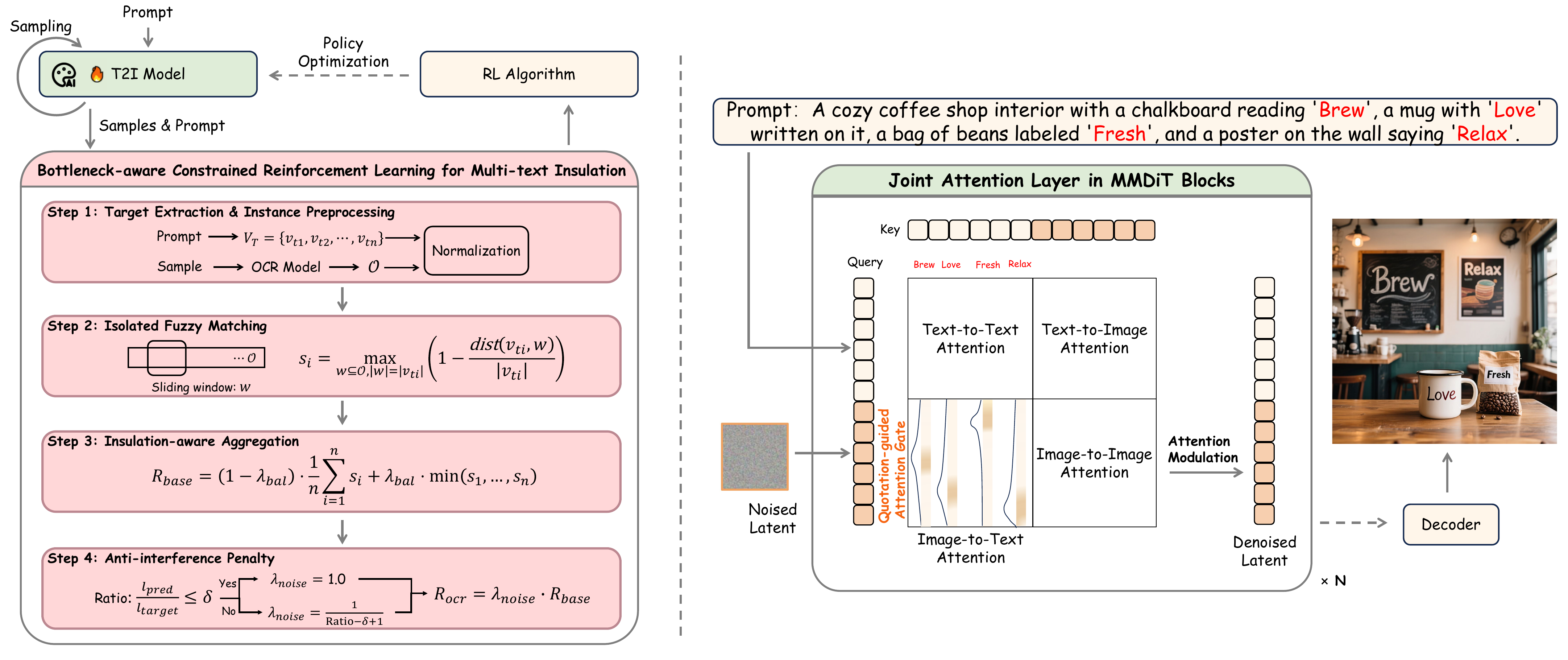
Technical Framework
TextCrafter combines multi-text insulation with quotation-guided text-oriented attention to suppress cross-text interference and keep visual text tokens concentrated in the correct regions.
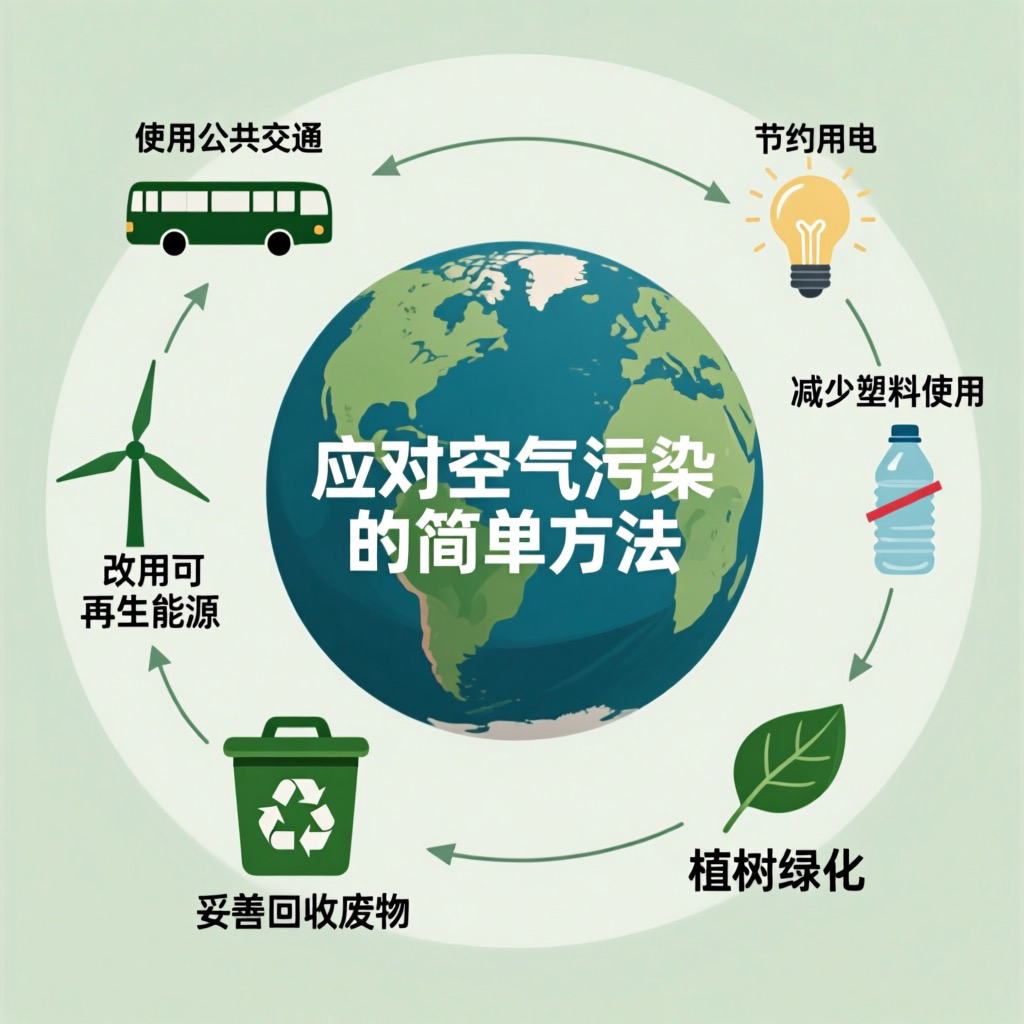
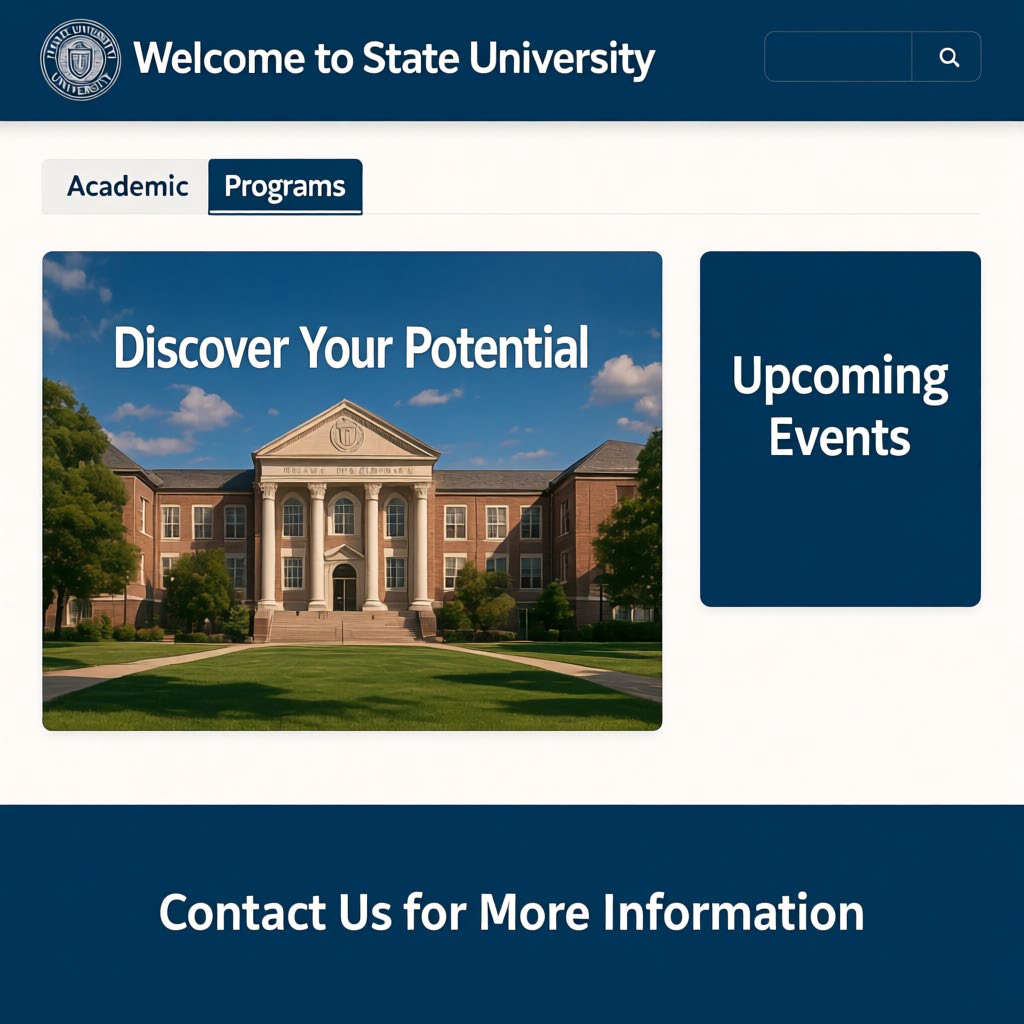
Experimental Results
Across CVTG-2K, CVTG-Hard, LongText-Bench, and Geneval, TextCrafter consistently improves text fidelity in complex multi-text scenes while preserving strong general text-to-image performance.
Model Performance Comparison
Quantitative comparisons in the paper show stronger word and span accuracy, higher normalized edit distance, and more robust long-text rendering on difficult benchmarks, while maintaining competitive quality on a general-purpose text-to-image benchmark.
`*` indicates results cited from previous papers.
Model | Word Accuracy↑ | NED↑ | CLIPScore↑ | VQAScore↑ | Aesthetics↑ |
|---|---|---|---|---|---|
FLUX.1 dev[Black Forest Labs 2024] | 0.4965 | 0.6879 | 0.7401 | 0.8886 | 5.91 |
GPT Image 1 [High]*[OpenAI 2025] | 0.8569 | 0.9478 | 0.7982 | - | - |
Gemini 2.5 Flash Image*[Google 2025] | 0.7364 | 0.8516 | - | - | - |
Seedream 4.5*[ByteDance 2025] | 0.8990 | 0.9483 | 0.8069 | - | - |
Qwen-Image*[Alibaba 2025] | 0.8288 | 0.9116 | 0.8017 | - | - |
Z-Image*[Alibaba 2025] | 0.8671 | 0.9367 | 0.7969 | - | - |
HunyuanImage-3.0*[Tencent 2025] | 0.7650 | 0.8765 | 0.8121 | - | - |
Longcat-Image*[Meituan 2025] | 0.8658 | 0.9361 | 0.7859 | - | - |
Emu3.5*[BAAI 2025] | 0.9123 | 0.9656 | - | - | - |
GLM-Image*[Z.ai 2026] | 0.9116 | 0.9557 | 0.7877 | - | - |
SD3.5 Large[ICML 2024] | 0.6548 | 0.8470 | 0.7797 | 0.9297 | 5.56 |
AnyText[ICLR 2024] | 0.1804 | 0.4675 | 0.7432 | 0.6935 | 4.53 |
TextDiffuser-2[ECCV 2024] | 0.2326 | 0.4353 | 0.6765 | 0.5627 | 4.51 |
RAG-Diffusion[ICCV 2025] | 0.2648 | 0.4498 | 0.6688 | 0.6397 | 5.58 |
3DIS[ICLR 2025] | 0.3813 | 0.6505 | 0.7767 | 0.8684 | 4.86 |
TextCrafter (Qwen-Image) | 0.9400(+13.4%) | 0.9757(+7.0%) | 0.8305(+3.6%) | 0.9570 | 5.90 |
Platform Gallery
Representative gallery samples highlight TextCrafter's ability to render complex visual texts across diverse scenes while mitigating text misgeneration, omissions, and hallucinations.






















BibTeX
@misc{tai2026investigatingtextinsulationattention,
title={Investigating Text Insulation and Attention Mechanisms for Complex Visual Text Generation},
author={Ying Tai and Nikai Du and Rui Xie and Zhennan Chen and Qian Wang and Zhengkai Jiang and Kai Zhang and Jian Yang},
year={2026},
eprint={2503.23461},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.23461},
}